About Me
My name is Zhenhua Yang (杨振华, Yeung Chenwa). I am an Algorithm Engineer in Taobao&Tmall Group of Alibaba in 2025. I received my Master degree from SCUT-DLVCLab in School of Electronic and Information Engineering, South China University of Technology, supervised by Prof. Lianwen Jin. I received my Bachelor degree from School of Automation Science and Engineering, South China University of Technology in 2022.
Previously, I have interned at Kling Team of Kuaishou (advised by Xin Tao) and International Digital Economy Academy (IDEA) (advised by Prof. Lei Zhang and Dr. Hao Zhang).
My research interests are focused on AIGC, Generative Model, and Large Multi-Modal Models. I am also devoted into the open source community.
GitHub / Google Scholar / Email / Zhihu / Linkin
News
∙ [05/2025] 🎉🎉🎉 Our work AutoHDR is accepted by ACL 2025 main and I am the project leader of this project. Also, the code is released in link.
∙ [02/2025] 🎉🎉🎉 Our paper HDR is selected as the oral presentation
∙ [12/2024] The inference code of our paper HDR is released in link.
∙ [12/2024] Our paper HDR is accepted by AAAI 2025 🎉🎉🎉, and the dataset, code and weight will be public soon. 🌹🌹🌹
∙ [07/2024] I will attend to ICML 2024 conference in person in Vienna, Austria. Open to have a disscussion or play with you. 🌹🌹🌹
∙ [06/2024] Now I am interned at International Digital Economy Academy (IDEA), supervised by Prof. Lei Zhang and closely work with Dr. Hao Zhang, where I am working on the topic of vision-language large model for video understanding.
∙ [05/2024] Our paper UPOCR is accepted by ICML 2024 🎉🎉🎉.
∙ [12/2023] 🔥🔥🔥 The 📺Hugging Face Demo and the 🧑💻Github Repository of FontDiffuser is released! Welcome to check it out.
∙ [12/2023] 🎉 The paper FontDiffuser is accepted by AAAI2024, which excels in complex character generation and large style variation. The code and demo will be released soon.
∙ [12/2023] Our paper UPOCR is released to arXiv.
Education
![]()
South China University of Technology
Sep. 2022 - Present
M.S student at SCUT-DLVCLab in School of Electronic and Information Engineering
![]()
South China University of Technology
Sep. 2018 - Jun. 2022
B.E student in School of Automation Science and Engineering
Experience

Alibaba - Taobao&Tmall Group
July 2025 - Present
AIGC Algorithm Engineer
Image Generation and Editting on E-commerce Scenarios.
Internship

KuaiShou - Kling Team
Jan. 2025 - Apr. 2025
Research Intern
Unifying Model for Generation and Understanding, supervised by Xin Tao.

International Digital Economy Academy (IDEA) - CVR
Jun. 2024 - Sep. 2024
Research Intern
Streaming Video Captioning and Understanding / Region Caption, supervised by Prof. Lei Zhang.

INTSIG - CamScanner
Mar. 2024 - May 2024
Engineering Intern
Editing documents in real-world scenarios.
Publications

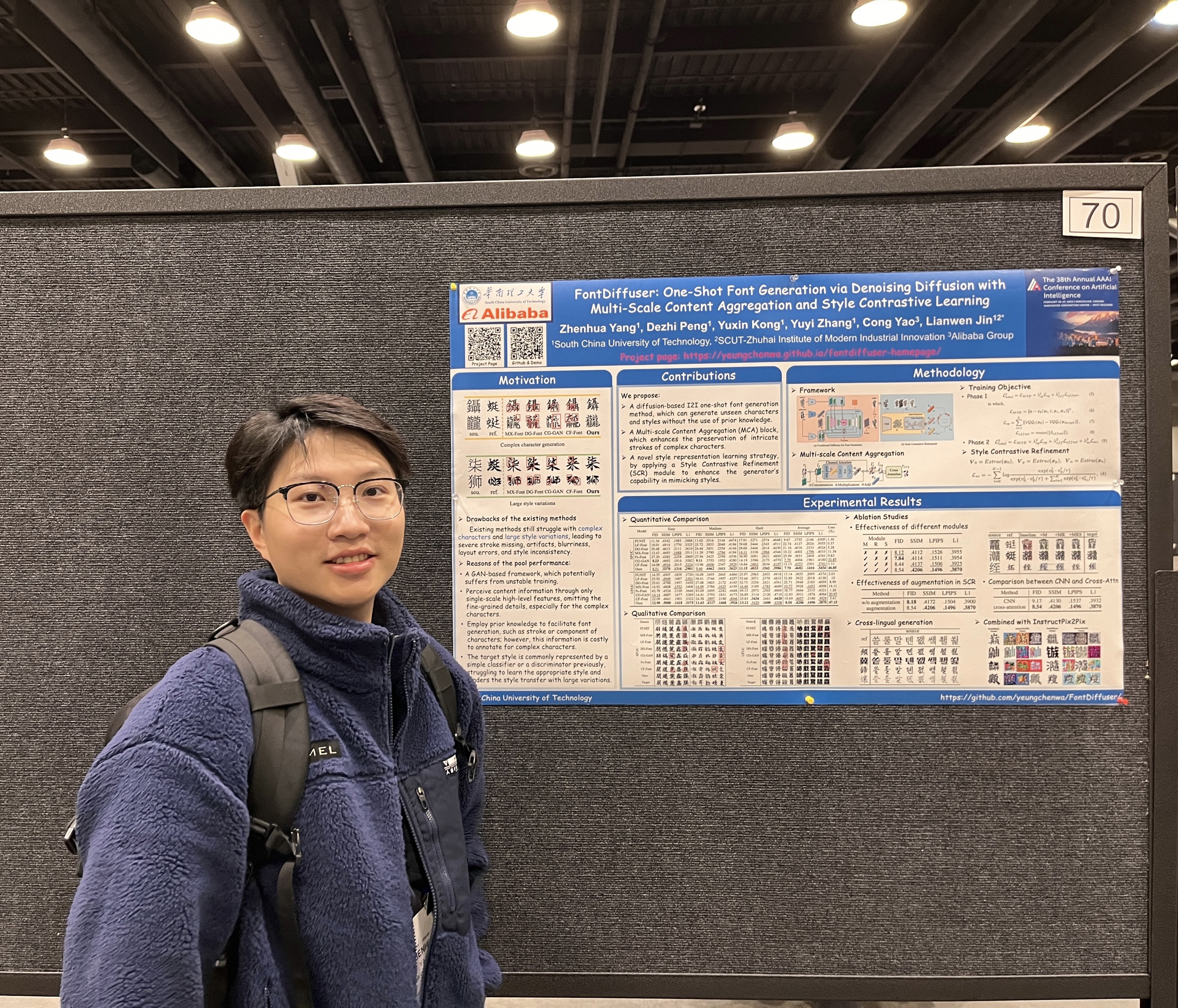
Predicting the Original Appearance of Damaged Historical Documents
Zhenhua Yang*, Dezhi Peng*, Yongxin Shi, Yuyi Zhang, Chongyu Liu, Lianwen Jin†
Proceedings of the AAAI conference on artificial intelligence (AAAI Oral), 2025


FontDiffuser: One-Shot Font Generation via Denoising Diffusion with Multi-Scale Content Aggregation and Style Contrastive Learning
Zhenhua Yang, Dezhi Peng, Yuxin Kong, Yuyi Zhang, Cong Yao, Lianwen Jin†
Proceedings of the AAAI conference on artificial intelligence (AAAI), 2024


UPOCR: Towards Unified Pixel-Level OCR Interface
Dezhi Peng*, Zhenhua Yang*, Jiaxin Zhang, Chongyu Liu, Yongxin Shi, Lianwen Jin†
International Conference on Machine Learning (ICML), 2024

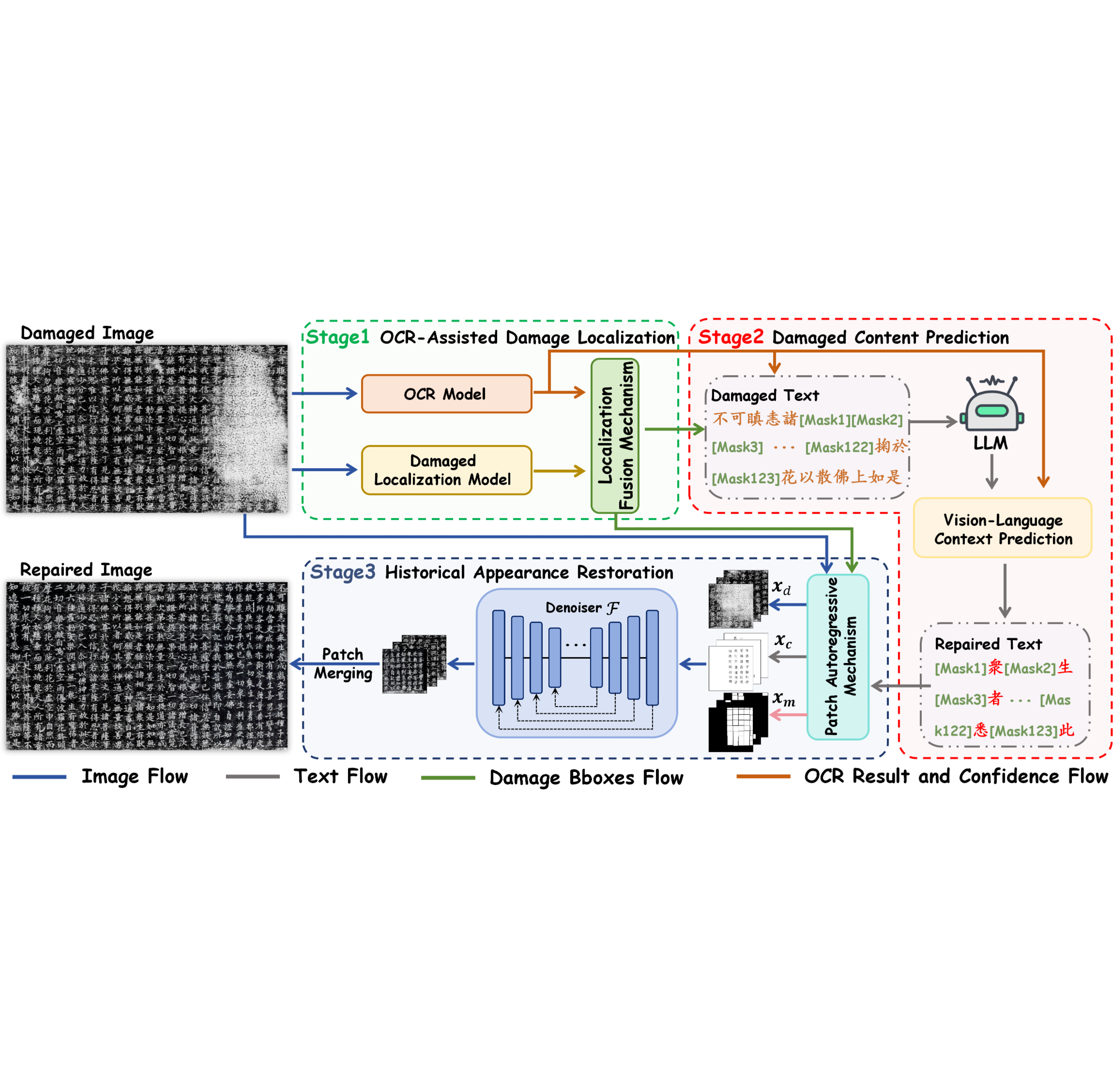
Reviving Cultural Heritage: A Novel Approach for Comprehensive Historical Document Restoration
Yuyi Zhang, Peirong Zhang, Zhenhua Yang*(project lead), Pengyu Yan, Yongxin Shi, Pengwei Liu, Fengjun Guo, Lianwen Jin†
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL main), 2025
Aesthetics is Cheap, Show me the Text: An Empirical Evaluation of State-of-the-Art Generative Models for OCR
Peirong Zhang, Haowei Xu, Jiaxin Zhang, Guitao Xu, Xuhan Zheng, Zhenhua Yang, Junle Liu, Yuyi Zhang, Lianwen Jin† Yuyi Zhang, Yongxin Shi, Peirong Zhang, Xinyi Zhang, Zhenhua Yang, Lianwen Jin† Yuyi Zhang, Yuanzhi Zhu, Dezhi Peng, Peirong Zhang, Zhenhua Yang, Lianwen Jin† Lichao Xiao, Jin-Gang Yu, Zhifeng Liu, Jiarong Ou, Shule Deng, Zhenhua Yang, Yuanqing Li Zhenhua Yang, Qing Jiang Zhenhua Yang Zhenhua Yang Jiaxin Zhang, Zhenhua Yang
preprint 2025
 -----
-----  ### MegaHan97K: A Large-Scale Dataset for Mega-Category Chinese Character Recognition with over 97K Categories
### MegaHan97K: A Large-Scale Dataset for Mega-Category Chinese Character Recognition with over 97K Categories
Pattern Recognition (PR), 2025
 ### HierCode: A Lightweight Hierarchical Codebook for Zero-shot Chinese Text Recognition
### HierCode: A Lightweight Hierarchical Codebook for Zero-shot Chinese Text Recognition
Pattern Recognition (PR), 2024
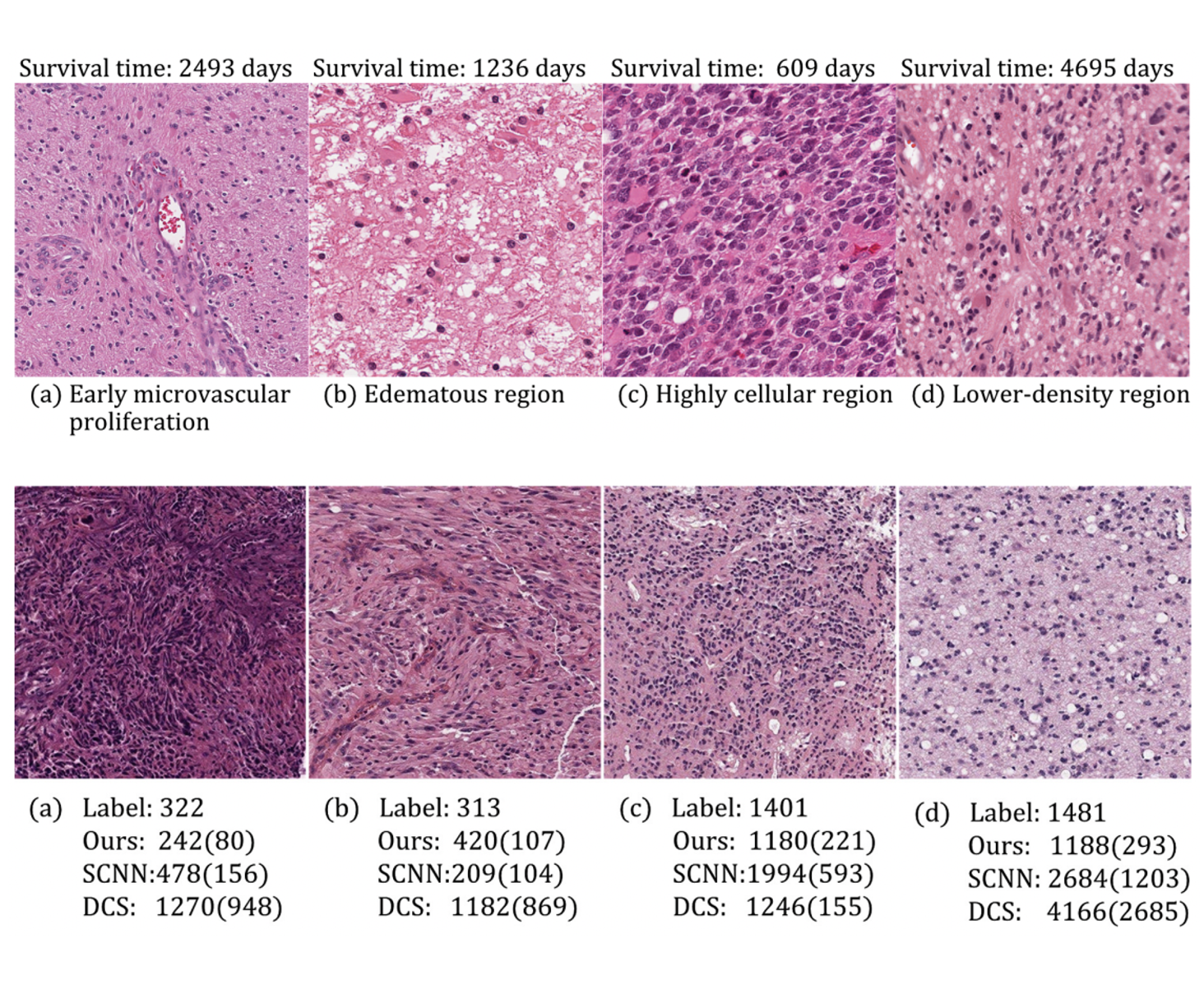 ### Censoring-aware deep ordinal regression for survival prediction from pathological images
### Censoring-aware deep ordinal regression for survival prediction from pathological images
Medical Image Computing and Computer Assisted Intervention, (MICCAI), 2020
 ### Optical Character Recognition with Segment Anything (OCR-SAM)
### Optical Character Recognition with Segment Anything (OCR-SAM)
Can SAM be applied to OCR? We take a simple try to combine two off-the-shelf OCR models in MMOCR with SAM to develop some OCR-related application demos, including SAM for Text, Text Removal and Text Inpainting. And we also provide a WebUI by gradio to give a better interaction.

 ### FontDiffuser: One-Shot Font Generation via Denoising Diffusion
### FontDiffuser: One-Shot Font Generation via Denoising Diffusion
We propose FontDiffuser, which is capable to generate unseen characters and styles, and it can be extended to the cross-lingual generation, such as Chinese to Korean.
 ### Recommendations of Diffusion for Text-Image
### Recommendations of Diffusion for Text-Image
A paper collection of recent diffusion models for text-image generation tasks, e,g., visual text generation, font generation, text removal, text image super resolution, text editing, handwritten generation, scene text recognition and scene text detection.

 ### Recommendations of Document Image Processing
### Recommendations of Document Image Processing
A paper collection of the methods for document image processing, including appearance enhancement, deshadow, dewarping, deblur, and binarization.
